
Category: Uncategorised
-
The Hashtag Syllabus: Part One

Marcia Chatelain, who started the #FergusonSyllabus almost exactly two years ago wrote about her work in The Atlantic: From the beginning of the situation in Ferguson, news reports alerted the public that Michael Brown was to start college soon. Before surveillance videos and photographs of protestors with their hands up were available, people saw a…
-
The Observer or Seeing What You Mean
If you are new to my writing, my talks and work tends to resemble an entanglement of ideas. Sometimes it all comes together in the end and sometimes I know that I’ve just overwhelmed my audience. I’m trying to be better at reducing the sheer amount of information I give across in a single seating.…
-
The Library Without a Map
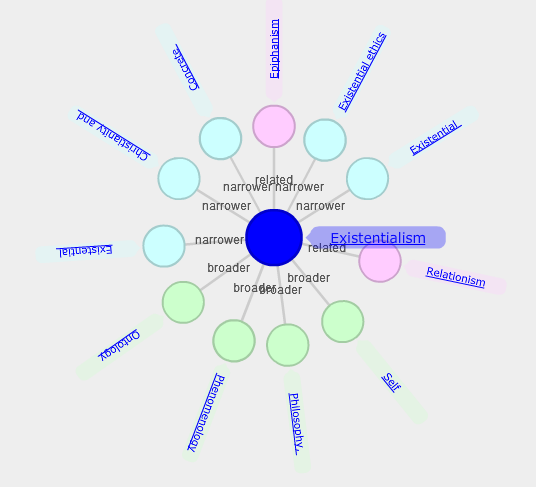
One of my favourite exercises from library school is perhaps one that you had to do as well. We were instructed to find a particular term from the Library of Congress Subject Heading “Red Books” and develop that term into a topic map that would illustrate the relationships between the chosen term and its designated…