
On October 24th, 2018, I gave a half-hour online presentation as part of a virtual conference from NISO called That Cutting Edge: Technology’s Impact on Scholarly Research Processes in the Library.
My presentation was called:

And here is the script and the slides that I presented:
Good afternoon. Thank you for the opportunity to introduce you to OpenRefine.
Even if you have already heard of OpenRefine before, I hope you will still find this session useful as I have tried to make a argument why librarians should invest investigate technologies like OpenRefine for Scholarly Research purposes.
This is talk has three parts.

I like to call OpenRefine the most popular library tool that you’ve never heard of.
After that this introduction, I hope that this statement will become just a little less true.

You can download OpenRefine from its official website OpenRefine.org
OpenRefine began as Google Refine and before that it was Freebase Gridworks, created by David François Huynh in January 2010 while he was working at Metaweb, the company that was responsible for Freebase.
In July 2010, Freebase and Freebase Gridworks were bought by Google adopted the technology and Freebase Gridworks was rebranded as Google Refine. While the code was always open source, Google supported the project until 2012. From that point on, the project became a community supported Open Source product and as such was renamed OpenRefine.
As an aside, Freebase was officially shut down by Google in 2016 and the data from that project was transferred to Wikidata, Wikimedia’s structured data project.
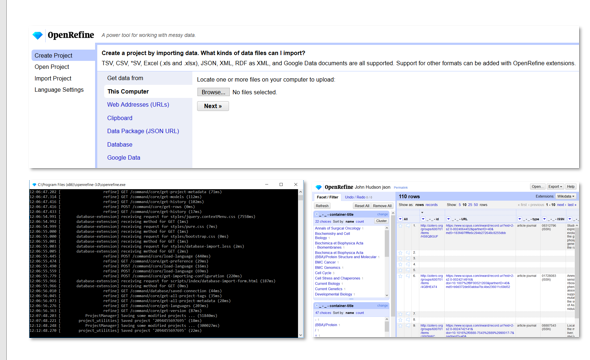
OpenRefine is software written in Java. The program is downloaded on to your computer and accessible through the browser. OpenRefine includes web server software and so it is not necessary to be connected to the internet in order to make use of OpenRefine.
At the top of the slide is a screen capture of what you first see when you start the program. The dark black window is what opens behind the scenes if you are interested in monitoring the various processes that you are putting OpenRefine through. And in the corner of the slide, you can see a typical view of OpenRefine with data in it.

OpenRefine has been described by its creator as “a power tool for working with messy data”
Wikipedia calls OpenRefine “a standalone open source desktop application for data cleanup and transformation to other formats, the activity known as data wrangling”.
OpenRefine is used to standardize and clean data across your file or spreadsheet.
This slide is a screenshot from the Library Carpentry set of lessons on Open Refine. I like how they introduce you to the software by explaining some common scenarios in which you might use the software.
These scenarios include
- When you want to know how many times a particular value (name, publisher, subject) appears in a column in your data
- When you want to know how values are distributed across your whole data set
- When you have a list of dates which are formatted in different ways, and want to change all the dates in the list to a single common date format
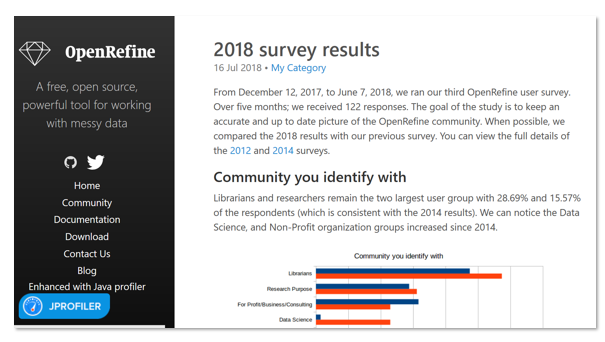
The software developers who maintain and extend the powers of Open Refine run regular surveys to learn more about their fellow users and in 2018 they found that their largest community was from libraries – a group that did not even register as its own category in the original 2012 survey.
So we know that the largest OpenRefine user group are librarians. Do we know how OpenRefine use measures up *within* the population of librarians? Unfortunately we don’t.
While we don’t expect such a specialized tool to be widely used across all the different types of librarians and library work, we have seen from this recent survey of metadata managers of OCLC Research Library Partners, OpenRefine is the second most popular tool used, second to MarcEdit.

That being said, once you know the power of OpenRefine, you will like myself see all these other potential uses for the tool outside of metadata cleanup. In August of this year, I read this tweet from fellow Canadian scholarly communications librarian, Ryan Reiger and sent some links that had instructions that illustrated how OpenRefine could help with this research question
When introducing new technology to others, it’s very important not to over sell it and to manage expectations.

But I’m not the only one who feels strongly about the power of OpenRefine. For good reasons, which we will explore in the second section of this talk

If you asked me what is the most popular technology used by librarians in their work and support of scholarship, I would say that one answer could be Microsoft Excel. Many librarians I know do their collections work, their electronic resources work, and their data work in Excel and they are very good at it.
But there are some very good reasons to reconsider using Excel for our work.

This slide outlines what I consider some of the strongest reasons to consider using OpenRefine. First, the software is able to handle more types of data than Excel can. Excel can handle rows of data. Open Refine can handle rows and records of data.
For many day to day uses of Excel it is unlikely you will run into the maximum capacity of the software but for those who work with large data sets, a limit of a 1 million and change rows might and can be a problem.
But the most important reason why we should consider OpenRefine is the same reason why it’s fundamentally different than Excel. Unlike spreadsheets software like Excel, no formulas are stored in the cells of OpenRefine
Instead formulas are used to transform the data and these formulas are tracked as scripts.
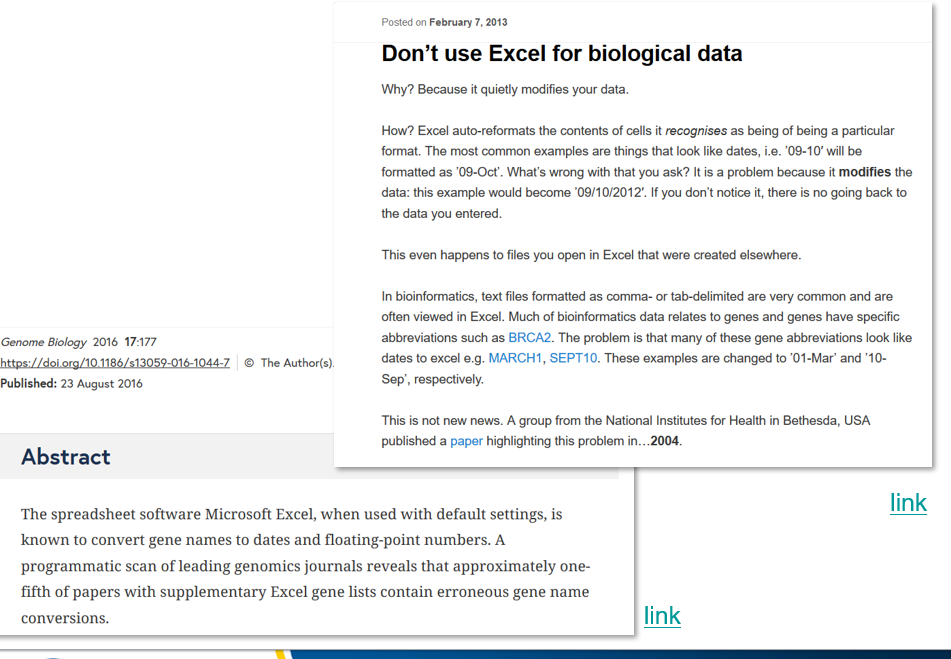
Not only do the cells of Excel contain formulas that transform the data presented in ways that are not always clear, Excel sometimes transforms your data without clearly demonstrating that it is doing so. According to a paper from 2016, one fifth of genomics journals had datasets with errors from Excel transforming gene names such as SEPT10 as dates.

I want to be clear, I am not saying that Excel is bad and people who use Excel are also bad.
We can all employ good data practices whether we use spreadsheets or data wrangling tools such as OpenRefine. I believe we have to meet people where they are with their data tool choices. This is part of the approach taken by the good people responsible for this series of lessons as Part of the Ecology Curriculum of Data Carpentry.

And with that, I just want to take the briefest of moments to thank the good people behind Software Carpentry and Data Carpentry – collectively now known as The Carpentries as I am pretty sure it was their work that introduced me to the world of OpenRefine
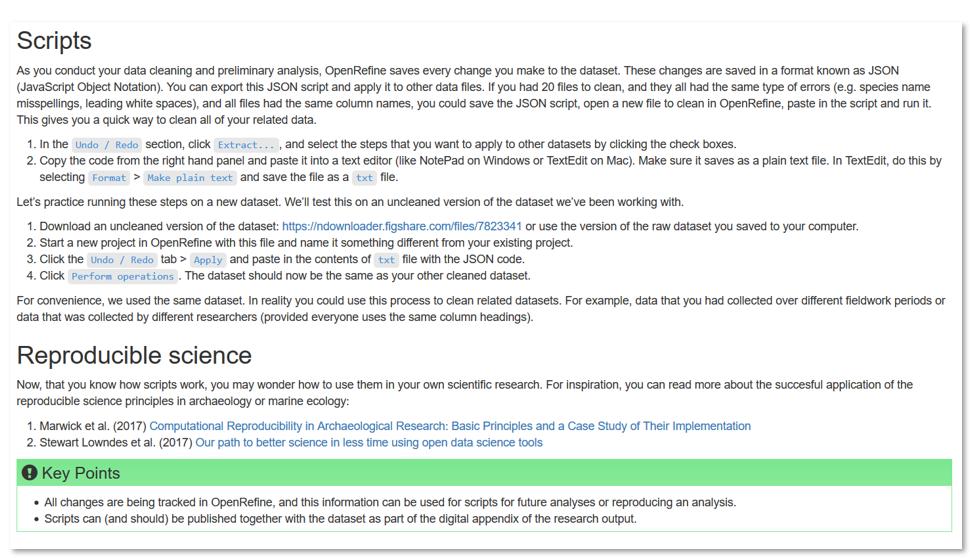
This slide is taken from the Library Carpentry OpenRefine lesson. There is too much text on the slide to read but the gist of the message is this: OpenRefine saves every change you make to your dataset and these changes are saved as scripts. After you clean up a set of messy data, you can export your script of the transformations you made and then you can apply that script to other similarly messy data sets
Not only does this ability saves the time of the wrangler, this ability to save scripts separately from the data itself lends itself to Reproducible Science.
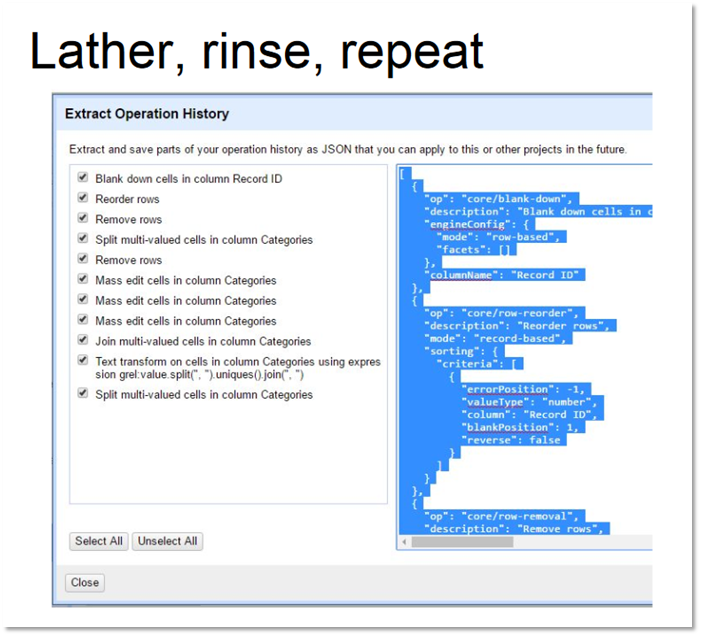
Here is a screenshot of a script captured in OpenRefine in both English and in JSON.
It is difficult for me to express how important and how useful it is for OpenRefine to separate the work from data in this way.
This is the means by which librarians can share workflows outside of their organizations without worrying about accidentally sharing private data.
As more librarians start using more complicated data sets and data tools for supporting research and their own research, the more opportunities there will be for embodying, demonstrating, and teaching good data practices.

I remember the instance in which I personally benefited from someone sharing their work with OpenRefine. It was this blog post from Angela Galvan which walked me through the process of looking up a list of ISSNs and running that list through the Sherpa Romeo API and using this formula on the screen to quickly and clearly present whether a particular journal allowed publisher PDFs to be added to the institutional repository or not.

And with that, here’s a bit of tour of how libraries are using OpenRefine in their work

This is from a walkthrough by Owen Stephens in which he used both MarcEdit and OpenRefine to find errors in 50,000 bibliographic records and make the corrections necessary so that they would be able to be loaded into a new library management system.
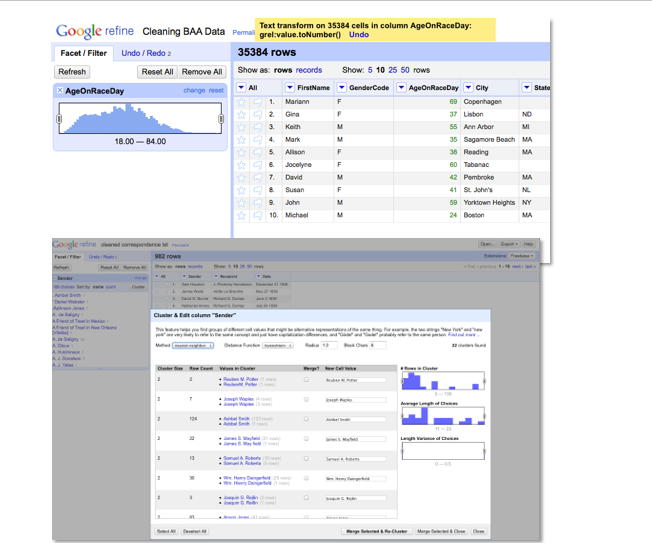
I haven’t spent much time highlighting it, but one of the most appreciated features of OpenRefine are related to its data visualizations that allow the wrangler to find differences that make a difference in the data.
The slide features two screens captures. In the lower screen, OpenRefine has used fuzzy matching algorithms to discover variations of entries that are statistically likely meant to be the same.
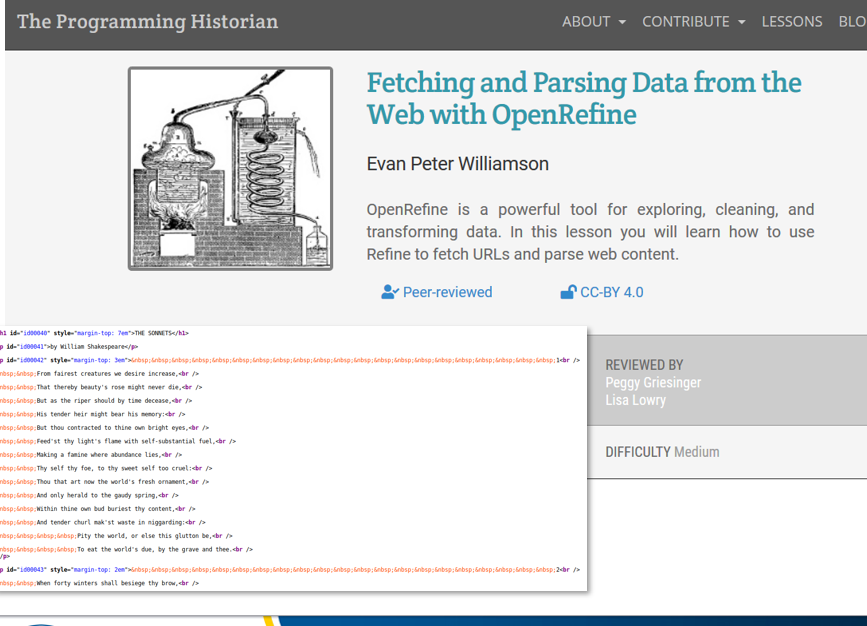
I had mentioned previously that I had used OpenRefine to use the Sherpa/Romero API. This ability of OpenRefine to allow users access to the API who may not be entirely comfortable using command-line scripting or programming should not be understated. That’s why lesson plans that use OpenRefine to perform such tasks as web scraping as pictured here, are appreciated.

With OpenRefine, libraries are finding ways to use reconciliation services for local projects. I am just going to read the last bit of the last line of this abstract for emphasis: a hack using OpenRefine yielded a 99.6% authority reconciliation and a stable process for monthly data verification. And as you now know, this was likely done through OpenRefine scripts.

OpenRefine has proved useful in preparing linked data…

And if staff feel more comfortable using spreadsheets, OpenRefine can be used to covert those spreadsheets into forms such as MODSXML

Knowing the history of OpenRefine, you might not be surprised to learn that it has built in capabilities to reconcile data to controlled vocabularies…
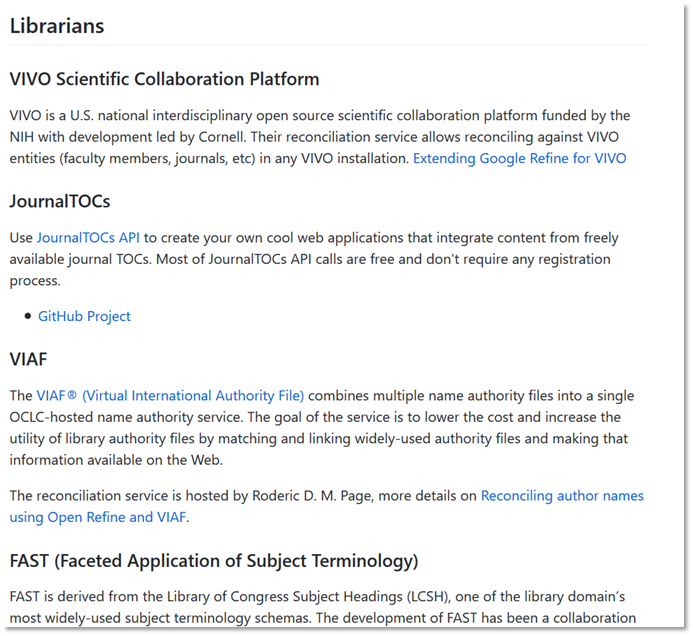
But you might be pleasantly surprised to learn that OpenRefine can reconcile data from VIVO, JournalTOC, VIAF, and FAST from OCLC.
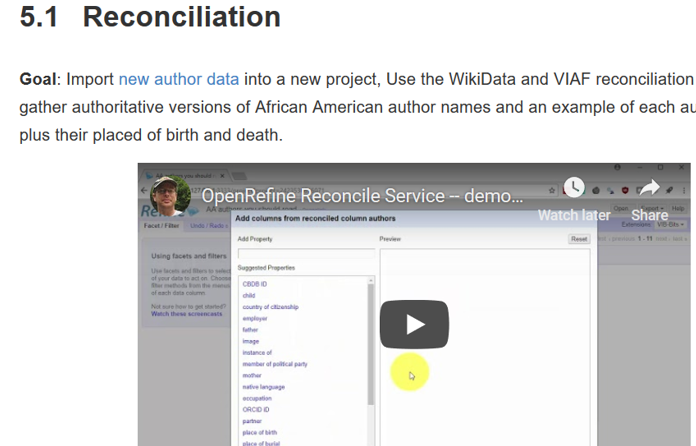
But the data reconciliation service that I’m particular following is from Wikidata.
In this video example, John Little uses data from VIAF and Wikidata to gather authoritative versions of author names plus additional information including their place of birth.
I think it’s only appropriate that OpenRefine connects to Wikidata when you remember that both projects had their origins in the Freebase project.
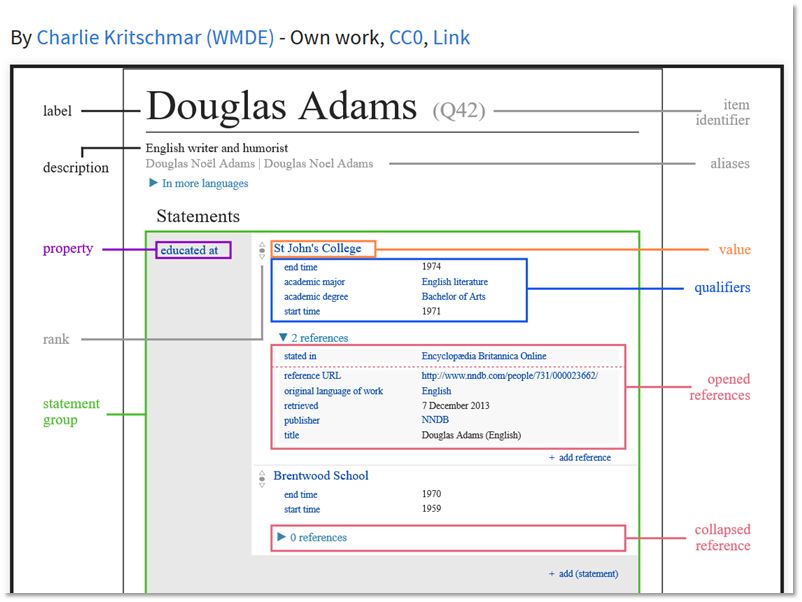
Wikidata is worthy of its own talk – and maybe even its own conference – but since we are very close to the end of this presentation, let me introduce you to Wikidata as structured linked data that any one can use and improve.
I was introduced to the power of Wikidata and how its work could extend our library work from librarians such as Dan Scott and Stacy Allison Cassin. In this slide, you can see a screen capture from Dan’s presentation that highlights that the power of Wikidata is that it doesn’t just collect formal institutional identifiers such as from LC or ISNI but sources such as AllMusic.

And this is the example that I would like to end my presentation on. The combination of OpenRefine and Wikidata – working together – can allow the librarian not only to explore, clean up and normalize their data sets – OpenRefine has the ability to extend our data and to connect it to the world.
It really is magic.
2 Responses to “Open Refine for Librarians”
[…] you could use OpenRefine and Wikidata to do this work for you in seconds. Here’s […]
[…] There are a series of tools available to allow for bulk upload into Wikidata. One of these tools is called OpenRefine – and it is already well used by many librarians. For more information, see OpenRefine for Librarians. […]