

On May 31 2023, I spoke at CALL ACBD 2023.
Slides and sources are also available. Other supplementary links are available via https://copystar.neocities.org/

This is a screenshot of my profile page of copystar@law.builders mastodon account. But I’m mostly on copystar@social.coop.
I am the Acting Law Librarian at the University of Windsor. I’ve only been at the Faculty of Law since September of last year, but I’ve been at the University of Windsor since 1999. I’ve held a variety of roles there, including as Scholarly Communications Librarian.





Please let me introduce you to Wikidata. This is its front page: www.wikidata.org. as you can see, it looks a lot like Wikipedia. And it is a part of Wikipedia. Although more accurately, we would say that Wikipedia and Wikidata are both part of the Wikimedia Foundation.
What is Wikidata? “Wikidata is a free and open knowledge base that can be read and edited by both humans and machines”. Remember this for later.

Wikidata started in October 2012. It was started to solve the problem with Wikipedia’s infoboxes.

Let’s suppose that you are about to go to a conference held in Hamilton, Ontario – a city that you are unfamiliar with. You are curious how large the city is, and so, without thinking, you go to Wikipedia (not the Canadian Census), and look up the city to find out its population. In doing so, you might pick up some interesting little factoids along the way, like who Hamilton is named after.

I just want to make a note of something very obvious: while we can describe something like a city in a million different ways, there are some properties of a thing that most of us ask about first, to better understand a thing.
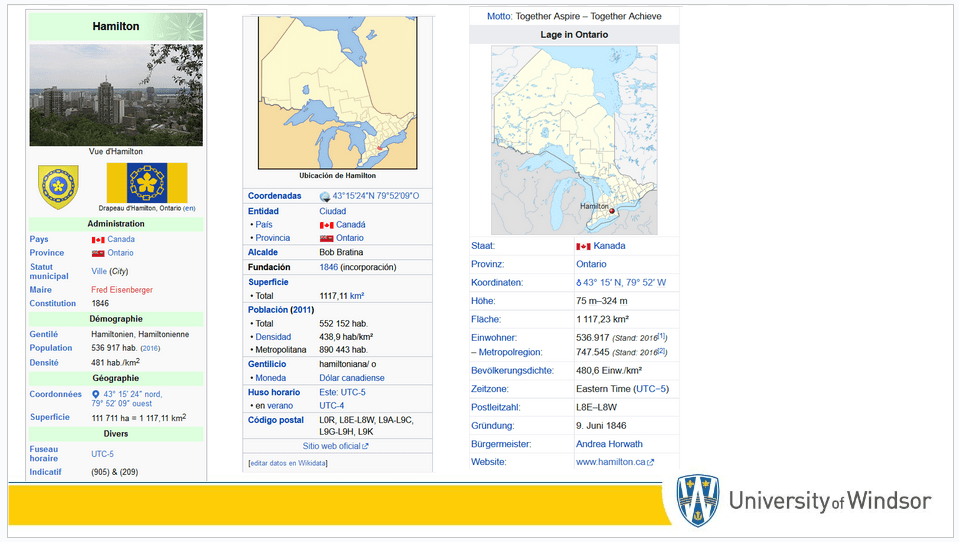
This is a slide that features three infoboxes from the French, Spanish, and German versions of Wikipedia. Not very many people know that there are more than 300 language versions of the free encyclopedia. English Wikipedia is the largest Wikipedia, but doesn’t mean that the other language Wikipedias aren’t large, themselves. Importantly, these language versions are all separate instances. If you update the English version, it doesn’t automatically adjust the other language versions of the page.
And this is one reason why Wikidata first came about. Everyone expects to have the population of a city available on its Wikidata page. Wouldn’t it be good if someone updates the population for one Wikipedia, if all the other language wikipedia pages could benefit from that contribution?

Remember: Wikipedia is not only free to use, it is free to re-use.

This is the Wikidata page for Hamilton.
When someone updated this page to give the population as described in the 2021 Canadian Census, it automatically updated all the different language Wikipedia infoboxes for the City of Hamilton.
And that’s because there is only one Wikidata page for the city of Hamilton, with a variety of translations – but only one source.

How can you be sure that the slide that I just showed you was for the city of Hamilton that’s in Ontario?

Wikipedia designates a unique item with a unique identifier. The item identifier (it starts with the the letter Q) allows us to differentiate Hamilton, Ontario from Hamilton, Bermuda.

Now because I am speaking in a room of fellow library workers and allies, I can speak to you in our shared language: Wikidata is the source of authority records for Wikipedia.

Furthermore, many Wikidata items also include other sources of authority records, including the Library of Congress. Wikidata is a fantastic resource when you want to find out a particular standardized identifier for an organization.

But wait there’s more! Wikidata allows contributors to build relationships between items using statements. This is Q42, the identifier for British writer, Douglas Adams.

In other words, Wikidata doesn’t just provide authority records, it provides this information as Linked, Open Data. For example, Marvin the Paranoid Android‘s Wikidata entry is described as a fictional robot who is present in a work called the Hitchhikers Guide to the Galaxy, which is has manifestations as a radio play, as a book, and as a movie. This is not unlike FRBR.

I am not going to talk about how libraries can make use of Wikidata as a platform for linked data. Largely because I don’t have to – there are great introductory pieces by people much closer to the work than I am. I recommend Wikidata: a platform for your library’s linked open data.

I first became involved in Wikipedia editing by volunteering at a local Art + Feminism editathon. Wikipedia editors host regular events like Art + Feminism, as a means to encourage better representation within Wikipedia which has largely been recognized as largely reflective of the interests and biases of its editors, the majority of which are western, white, and male.
When I found out that there was going to an editathon on my campus dedicated to populating Wikipedia with entries celebrating indigenous athletes, I used that as an opportunity to add a list of Tom Longboat Award Winners to Wikidata.

This is a screen capture of a visualization of the results of the work on that day. This is the timeline view of a Wikidata query. You can see it as a live embed at: https://librarian.aedileworks.com/2017/12/19/the-tom-longboat-awards-as-wikidata/

If I click on the table view of this Wikidata query, you will see that this is just a list of people who have won the Tommy Longboat Award.
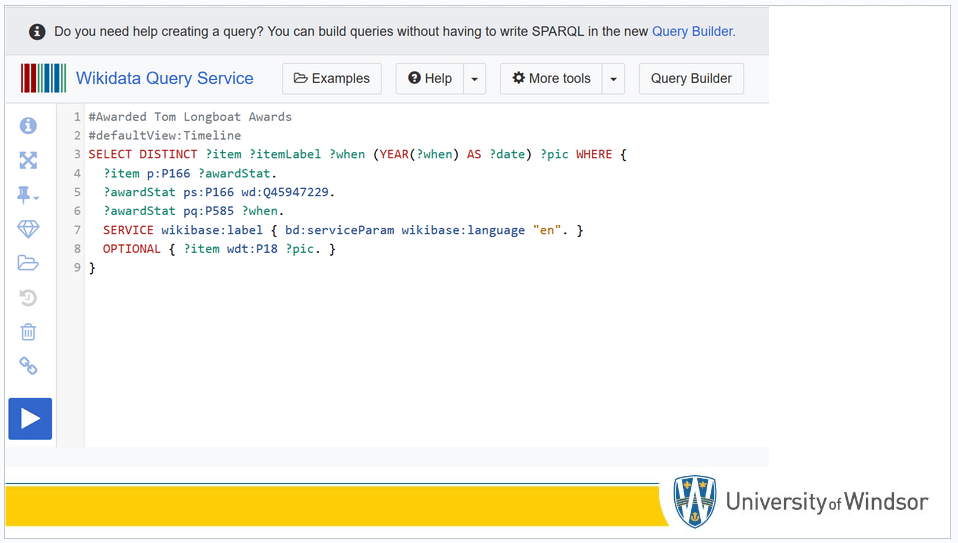
The previous table is the result of this Wikipedia Query, which is not dissimilar to SQL and SPARQL.

I know this looks very cryptic. Please know that I did not write this by hand. I used this tool to create this query.
This is how I built this query: I asked to find all the items that had a property of Award Received with the value being the Tom Longboat Awards.
It takes a little while to wrap one’s mind around the terminology and what the query service can do. But I can do it. And I think you can do it too.

Why should law librarians, library workers, and their allies consider adding to Wikidata and Wikipedia?

For me, the most compelling answer is this – Wikipedia is the place where our students, our colleagues, and our family members go to, when they need factual information.
Our students do so, even when they have healthier information options available to them.
By the way, you can no longer find this post on the windsorlawdebate instagram account. Shortly after I found their account and the day after I recommended it to my colleagues they posted this:

I am sorry.
And I want to be clear, I don’t want sound like I’m picking on students for these memes or for their confession that they use Wikipedia.
I also use Wikipedia.

There is a body of evidence that suggests that in many disciplines, including that of law, you can find a higher than expect amount of text that matches with text from Wikipedia. This suggests that Wikipedia is a source of influence not just to law students but, as this paper claims, to judges.

Canadian Law is not well represented in Wikidata. At the time in which I had to submit my slides, there were only 6 Wikidata items with Canlli IDs.

And just to let you know, when you want to do this sort of search, you would use Wikidata’s Query Builder using this query string: https://w.wiki/6nTr

More than ten years ago, York Librarian Tim Knight wrote about his hopes that CanLii could become a source of Open Linked Data for Canada. That did not come to pass. But what Wikidata exists and gives us, or anyone, the ability to create a linked data project using its tools and tutorials as a platform as an alternative.

You might be asking, but why? What’s the use of adding linked structured data to Wikipedia?
And in many ways, we’ve already covered the reasons. It can be very useful to have a system that has authority control as this can better ensure you are getting information about the thing that you have in your mind.

We now already know that Wikidata can link to CanLii…

Wikidata also provides the ability to connect to other sources of text and authority.

And it can provide additional sources of legal citation.

Wikidata can help connect readers to the source documents of legal history.

This is the Wikipedia entry for Person’s Day. And while I have your attention, please note that this page has, in the left hand menu, a link to this item’s Wikidata Data page.
This is one of my favourite pages on Wikipedia because just over ten years ago…

I tried to create the Person’s Day page on Wikipedia, but was, at that time, unsuccessful in convincing a Wikipedia editor that Person’s Day was considered a notable enough day to be worthy of such a page.
The question and sometimes back and forth dialogue with other editors about what is considered Notable enough can still happen if you are a Wikipedia editor. This is less of a problem when you work in Wikidata. There is a lot less drama there. That being said, you must ensure that your new Wikidata items are unique and accurate.

We could use Wikidata to provide structured ways to query law.

As I mentioned before, there is not a corpus of Canadian legal data in Wikidata to really get an understanding of what it can be done with it, but if you start playing around with the US legal information, you can start to see what kind of searches you can do with Wikidata.
In this example, for people in the back, this is a query that returns US Supreme Court Decisions that had a majority opinion by Harry Blackmun that was a concurring opinion.

But as we already know, we can’t perform these types of structured queries of Canadian supreme court decisions in Wikidata, because the data is not there. But luckily we don’t all have to type the data in by hand as Wikidata allows for bulk uploads of tabular data.

There are a series of tools available to allow for bulk upload into Wikidata. One of these tools is called OpenRefine – and it is already well used by many librarians. For more information, see OpenRefine for Librarians.

Ok, so now we have a tool. But now we just need cleaned, deduped, and structured data and metadata… and everyone in this room will know, that’s not an easy thing to get your hands on. But there are sets of data that are available.

York University’s Refugee Law Lab recently released ten years worth of Federal Court of Appeal Decisions: https://refugeelab.ca/bulk-data/fca/.

And then there is the Lenezer Slaught Supreme Court of Canada Database that describes each of its reported decisions since 1954.

We can do it. But should we? I would say, yes.

What could be worse than judges using Wikipedia to make their decisions?

At this point in the conference, I think we all know the answer to this question.

If you are as old I as I, you might have had the strangest feeling that this all feels weirdly familiar.


On the screen is the beginning of a wonderful article by Barbara Fister and Alison J. Head called Getting a Grip on Chat-GPT in which they find parallels to the reactions we had with Wikipedia and with those that we are currently feeling with Large Language Models.

I don’t know what this portends to our profession’s approach to large language models, but most librarians are still hesitant about adding to Wikipedia.

I mean CALL/ACBD doesn’t even have its own entry yet!


Before commercial tools were readily available, librarians made their own sources. The Canadian Periodical Index began from the work of Windsor Public Librarians in 1928.

I recently learned that the Windsor Law library staff in the 1970s created a digest, that acted “a service which summarized the content of bills and tracked their progress from introduction to royal assent.”

There has been so many mentions of ChatGPT, AI, and large language models during this conference. These popularized systems are stochastic parrots. They generate autotuned and autocompleted text based on the shape of letters.
I hope that my talk has been a useful introduction to an alternative to these black box systems. I hope you can take some comfort knowing that there still exists an alternative means to connect verifiable references to offered facts.
Wikipedia is a source that our students, our staff, our faculty, our families, and our communities already understand and can assess due to their existing familiarity. Wikipedia is frequently used to train AI systems. This means, when we improve Wikipedia – we can improve these systems by proxy.
Wikipedia is a community that shares many of the same values as our profession.
This is work we’ve done before. This is work we can do now. And I think we’re better when we work together.
Thank you.
2 Responses to “What is Wikidata and Why You Should Do Data Entry for the Greater Good”
[…] work. For example, last year at the CALL 2023 Conference, I gave a presentation entitled, “What is Wikidata and Why You Should Do Data Entry for the Greater Good“, CALL ACBD 2023, Hamilton, ON, May 31 […]
[…] All four of those Wikipedias link to her Wikidata page: https://www.wikidata.org/wiki/Q2900380. As you recall, Wikidata was created to share facts between the various language Wikipedia. […]